


Intro: From Reactive to Strategic
For years, data teams were stuck in reactive mode—chasing bugs, cleaning up messy reports, and answering “what went wrong?” after it was too late.
But that’s changing.
As businesses embrace shift-left thinking, data teams are stepping out of the shadows and into the spotlight—not just as support, but as strategic partners. This part of the series explores that transformation: from janitor to architect, and how it's reshaping team structure, workflow, and trust across the business.
The Data Supply Chain…and where it breaks
Let’s start with a concept: the data supply chain.
This model treats the flow of data through an organization like a physical supply chain—moving from raw materials (like user clicks or transactions) through stages of processing, transformation, and validation, before becoming a usable product (a dashboard, report, or ML model).
If you prefer food metaphors (who doesn’t?), here’s the breakdown:
Raw ingredients → Clicks, transactions, user feedback
Food prep → Cleaning, validating, transforming
Packaging → Modeling, storing, structuring
Final dish → Dashboard, report, AI decision
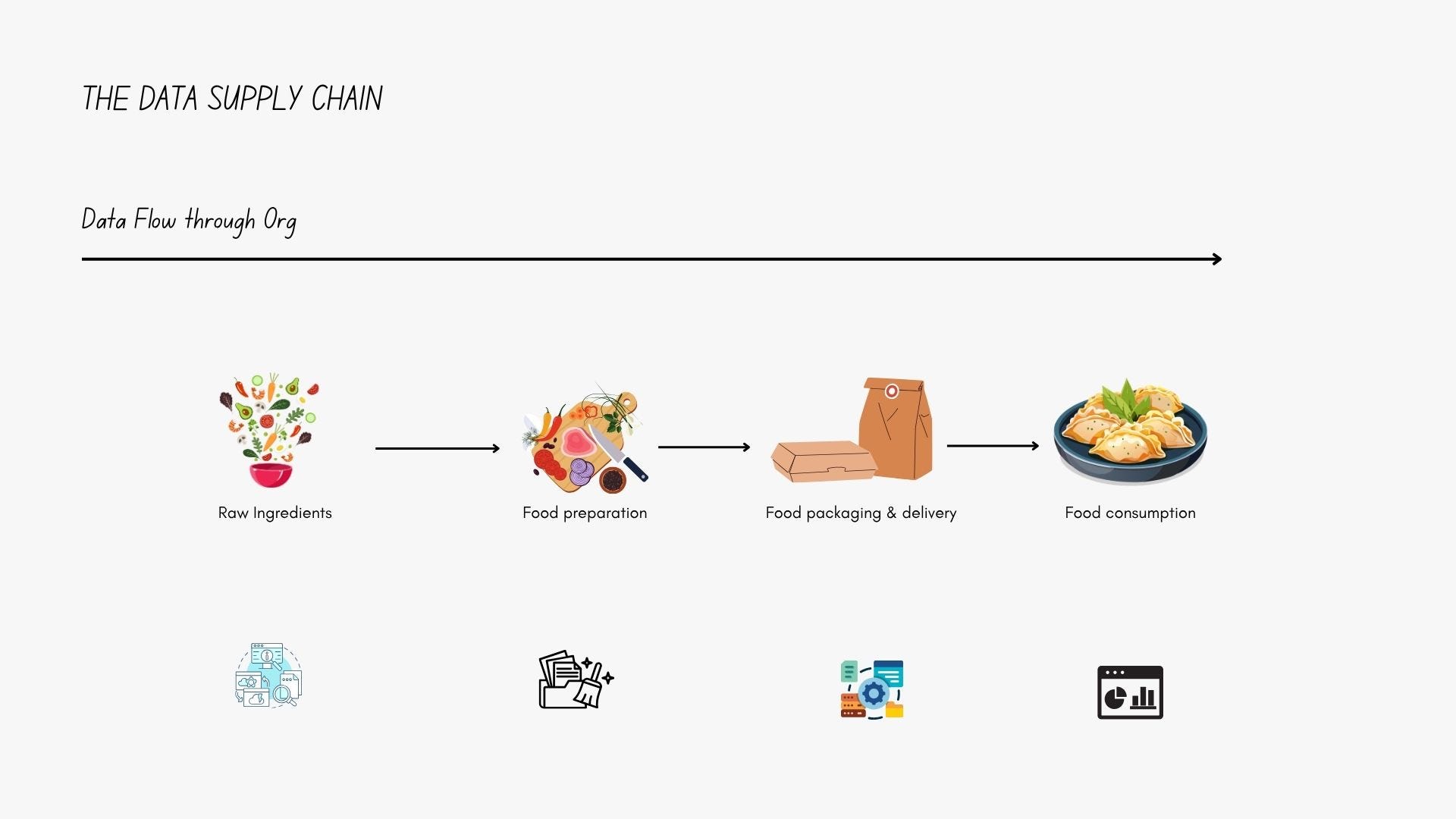
Now imagine a restaurant where no one checks the ingredients until the plate is already on the table.
That’s how most companies treat their data today.
Shift-left thinking says: catch quality issues upstream—right where the data is created, logged, and passed between systems. And modern data teams? They’re not just serving the meal. They’re redesigning the kitchen.
They build test suites, manage schemas, define metrics, and ensure clean handoffs across the supply chain. They don’t just react to problems—they prevent them from happening.
From Cleanup Crew to System Thinkers
In the traditional org chart, data teams were often tucked under IT, engineering, or even finance. That wasn’t just about hierarchy—it reflected how they were seen: as internal service providers.
Their role?
React to incoming requests
Pull ad hoc numbers
Patch broken dashboards
They were like a digital cleanup crew.
Take this example:
Marketing launches a campaign but forgets to tag channels. Sales enters inconsistent region codes in the CRM. Product logs a signup event as sign_up_complete, while another team logs it as signup_done. The data team? They’re stuck trying to stitch together chaos.
But in today’s world of real-time decisioning and AI, that structure simply can’t hold.
You can’t ask your AI to make smart predictions if your team is still spending 70% of their time cleaning up behind other departments. You need data that’s right at the source—which means your data team needs to be upstream, not downstream.
Cross-Functional by Design
This shift is making data teams radically more cross-functional.
Modern teams aren’t waiting around for JIRA tickets—they’re embedded in product squads, marketing pods, and ops teams.
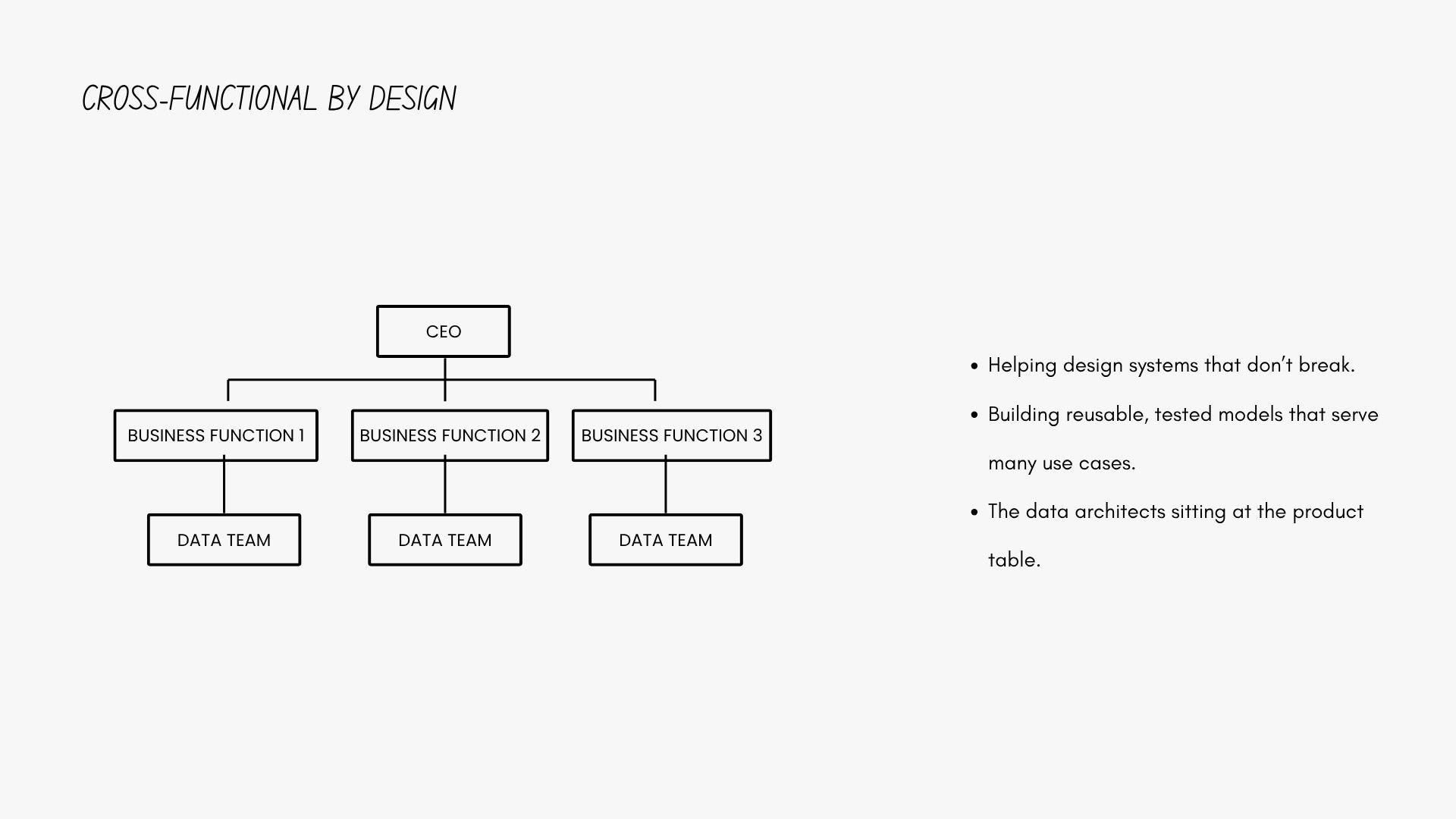
Here’s why it works:
Being close to the source means better data design
Data engineers can advise on logging and structure
Analysts can shape what gets captured from the start
Teams start collaborating before problems show up
This shift even changes the org chart. Data people are now domain-embedded. They advise on strategy, not just dashboards. They're not just answering “what happened?” but helping shape “what should we build next?”
To put it another way:
Instead of fixing dashboards, they’re designing systems that don’t break
Instead of patching SQL, they’re building reusable, tested models
Instead of acting as janitors, they’re acting as architects
And this isn’t just more efficient—it’s more fulfilling.
The New Model: Data as a Product, Data Teams as Architects
Let’s introduce a concept that brings it all together: Data as a Product.
Popularized by Zhamak Dehghani’s Data Mesh philosophy, this model flips the traditional thinking. Instead of treating data as something that gets piped from source to report, we treat each data asset like a product with:
A clear purpose (what decision does it inform?)
Known users (who depends on this?)
Assigned owners (who ensures its quality?)
SLAs (how fresh, complete, and accurate should it be?)
This mindset turns data teams into product thinkers, not just SQL writers.
They ask:
“What data assets do we maintain?”
“Are they reliable enough to be used in AI models?”
“Can users trust them like an API—blindly and confidently?”
That requires:
Stakeholder collaboration at the design stage
Automated testing and monitoring
Clear documentation and versioning
It’s not just building pipelines—it’s building products people rely on.
🛠️ The Tooling is Catching Up
We’ll go deeper into tooling in the next part of the series, but here’s a quick preview:
dbt lets teams define transformations as modular, testable code
DataHub, Atlan, and Unity Catalog help document and discover data assets
Monte Carlo and Bigeye alert you when data breaks before anyone else notices

And all these tools reinforce one powerful behavior: treat data like software.
That means version control. Testing. Deployment pipelines. Monitoring. Documentation. Ownership.
The result?
Fewer late-night dashboard fixes. More time spent building reliable systems.
The Shift in Skills and Mindsets
It’s not just the tools that are evolving—the people are too.
Here’s what makes today’s data professionals stand out:
Product thinking — knowing users, trade-offs, and impact
Communication — translating data logic into human language
Collaboration — working with engineers, PMs, and stakeholders
Ownership — taking responsibility for outcomes, not just outputs
That’s why we’re seeing roles like:
Analytics Engineer
Data Product Manager
DataOps Lead
These aren’t fluff titles—they reflect the growing maturity of data teams as true builders and business enablers.
TL;DR
To wrap it up:
Data teams are no longer janitors—they’re architects building for scale and trust
Shifting left means getting involved early—at design, logging, and collaboration stages
Cross-functional teams prevent downstream chaos
“Data as a product” means intentional design, ownership, and reliability
The best data teams today don’t just answer questions—they design systems that ask better ones
🔜 Up next in Part 3: The Tools That Make Shift-Left Work
We’ll walk through real platforms and workflows that help data teams test, monitor, and version-control their pipelines—before things break.







